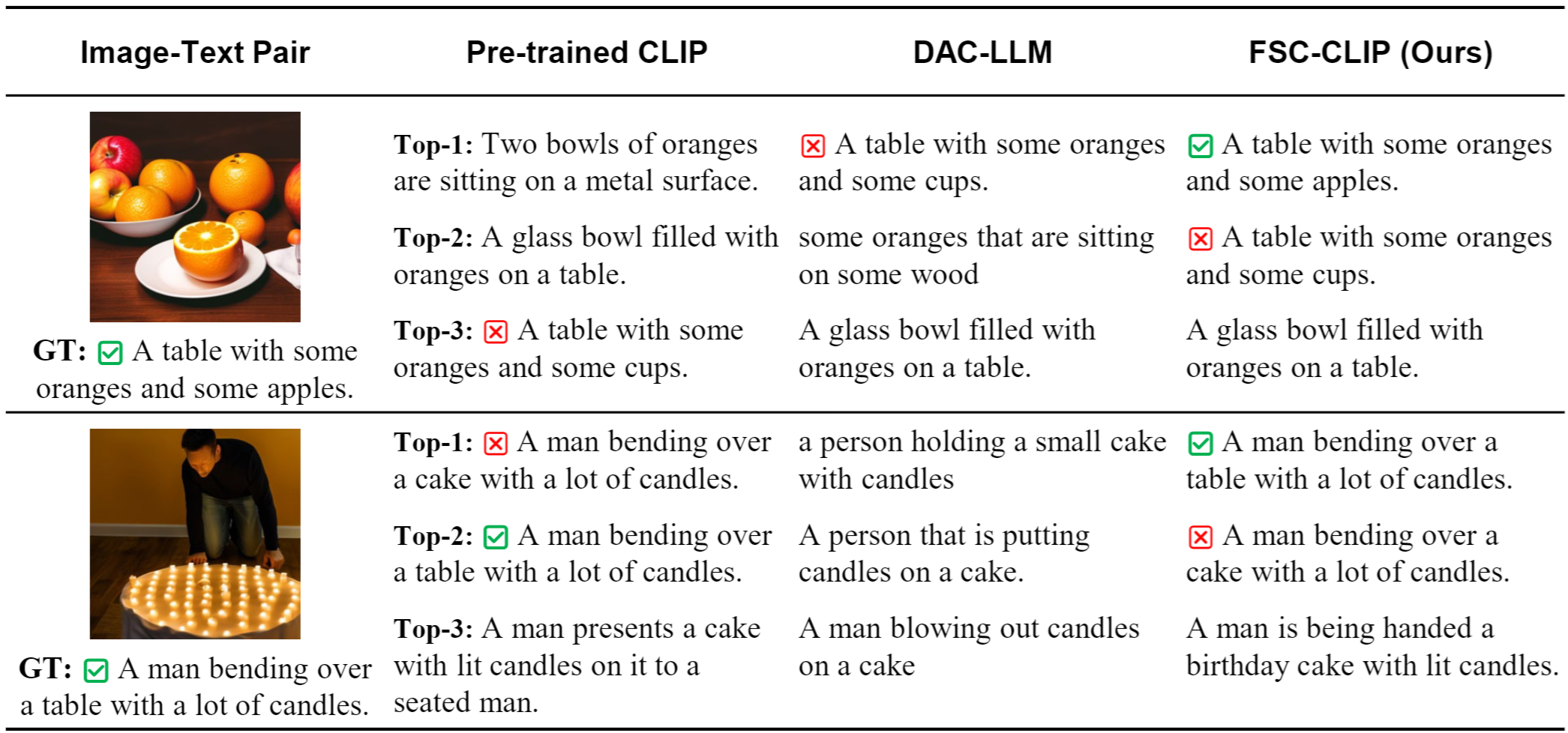
In this paper, we propose a new method to enhance compositional understanding in pre-trained vision and language models (VLMs) without sacrificing performance in zero-shot multi-modal tasks.
Traditional fine-tuning approaches often improve compositional reasoning at the cost of degrading multi-modal capabilities, primarily due to the use of global hard negative (HN) loss, which contrasts global representations of images and texts. This global HN loss pushes HN texts that are highly similar to the original ones, damaging the model's multi-modal representations.
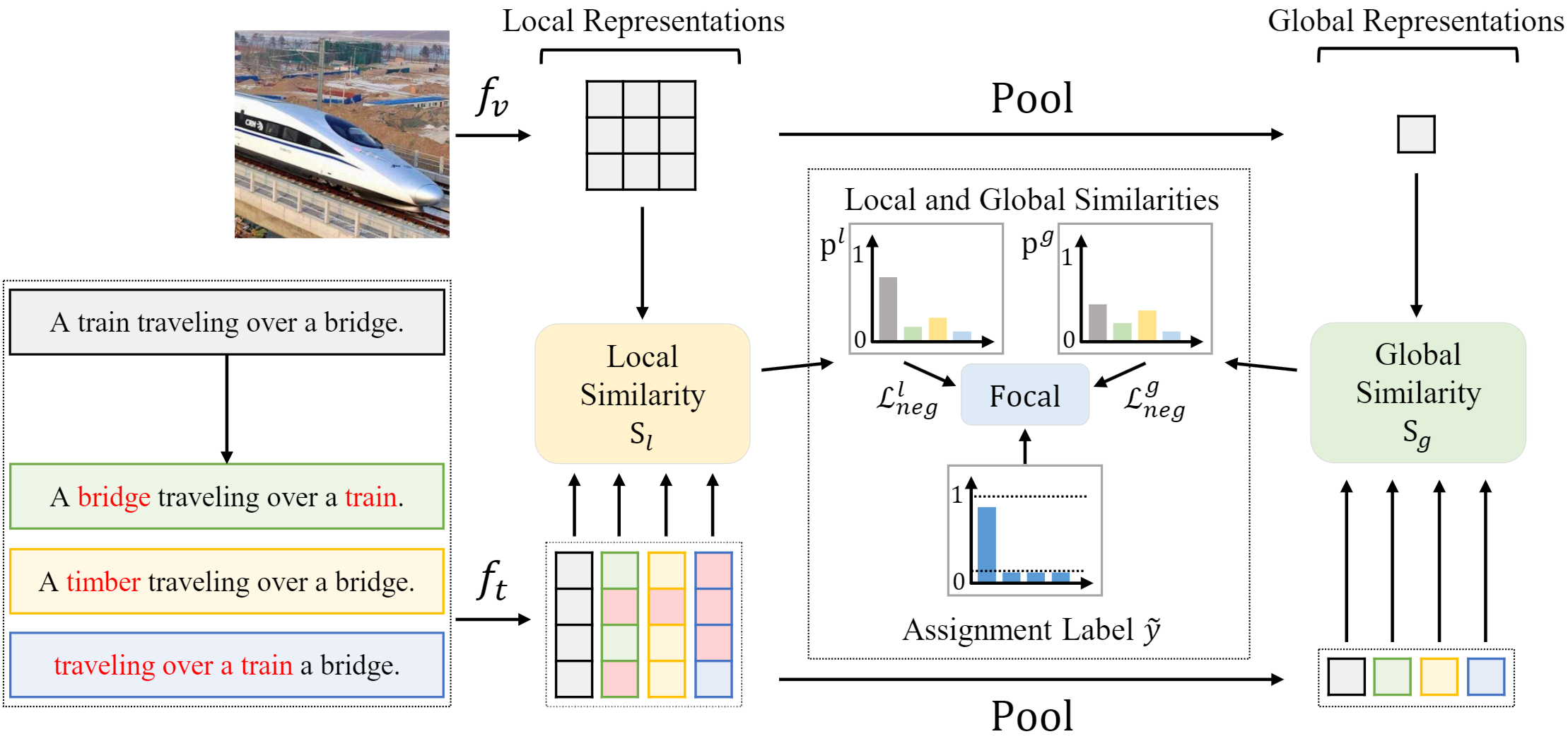
To overcome this limitation, we propose Fine-grained Selective Calibrated CLIP (FSC-CLIP), which integrates local hard negative loss and selective calibrated regularization. These innovations provide fine-grained negative supervision while preserving the model's representational integrity.
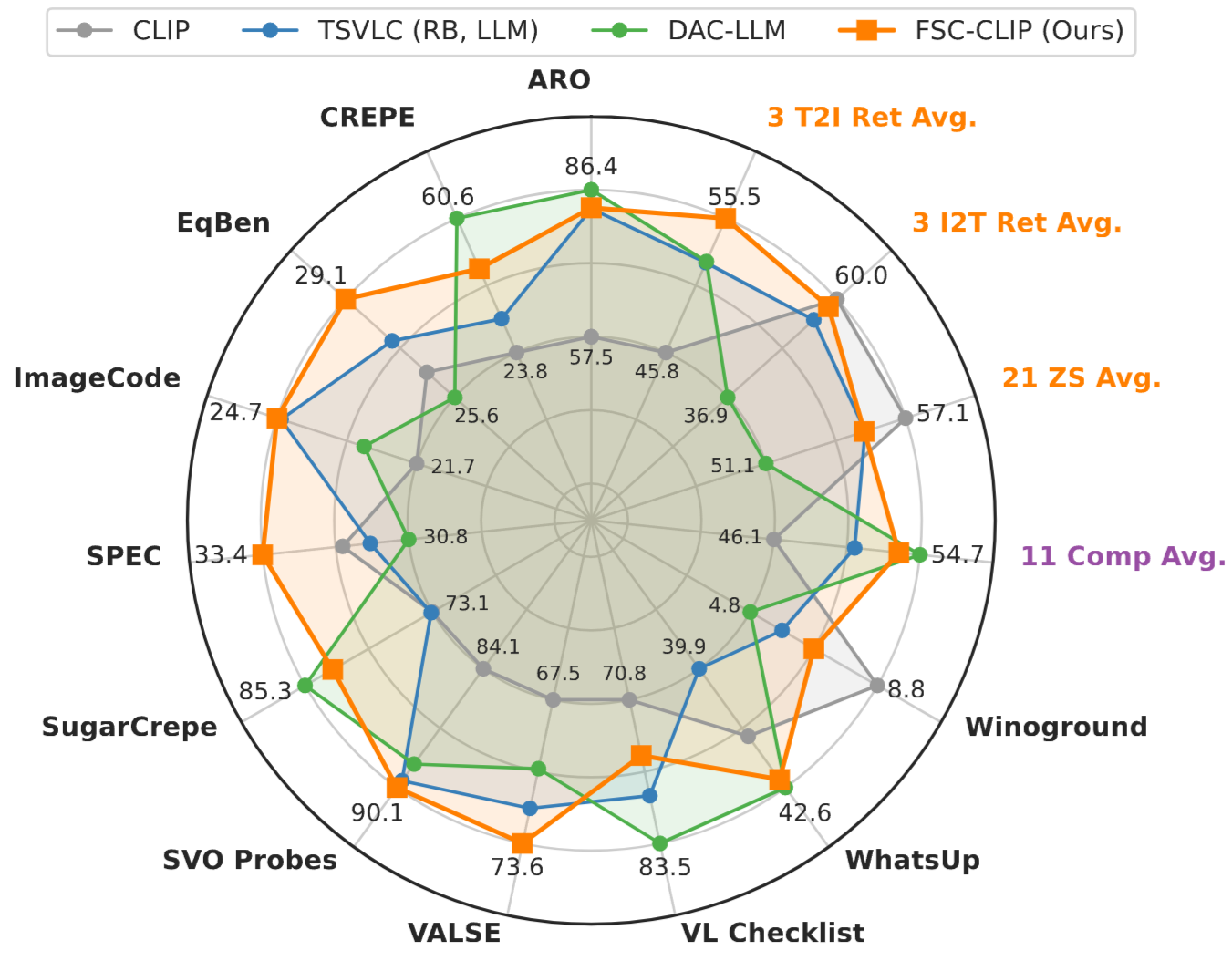
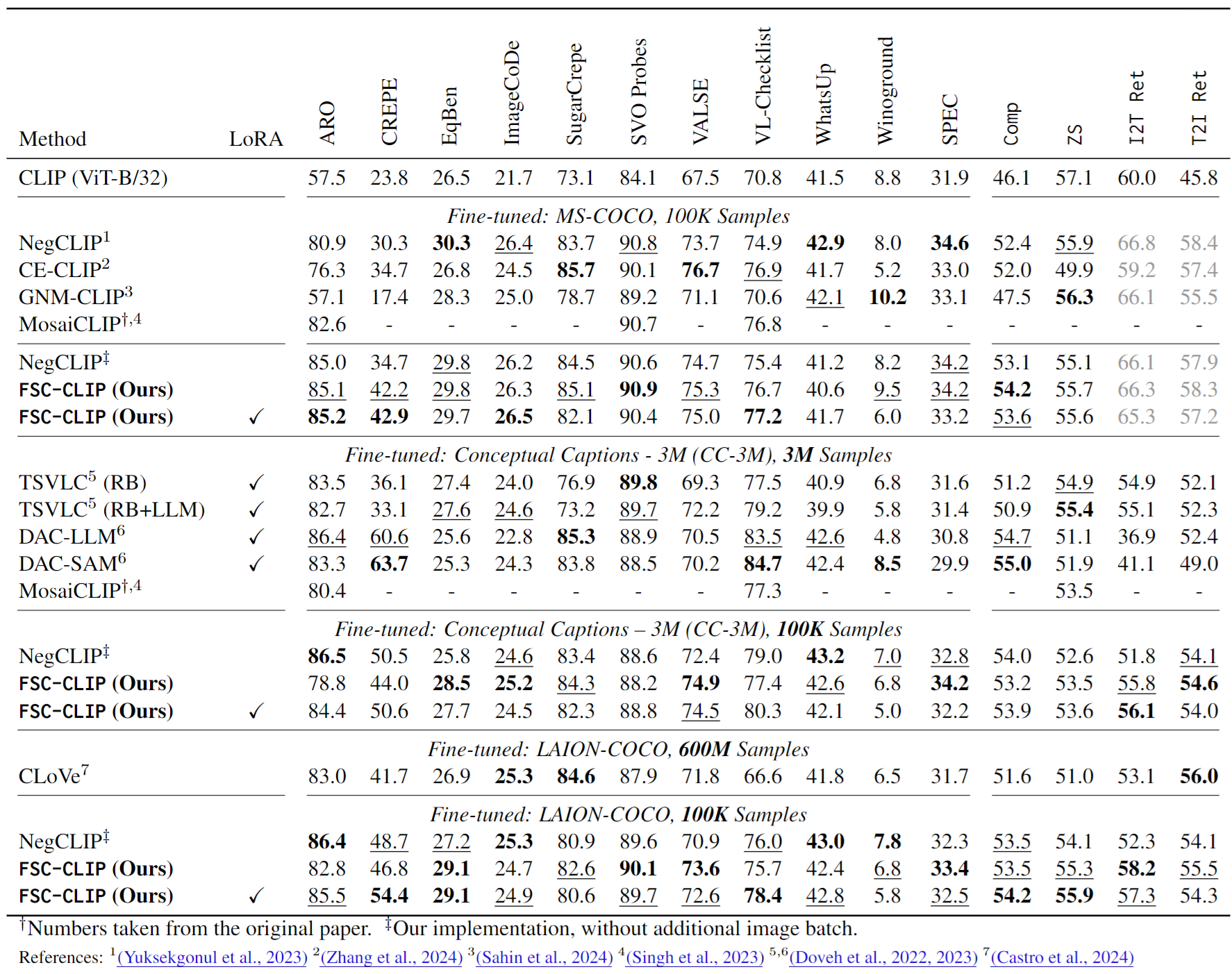
Our extensive evaluations across diverse benchmarks for both compositionality and multi-modal tasks show that FSC-CLIP not only achieves compositionality on par with state-of-the-art models but also retains strong multi-modal capabilities.
Compositional reasoning remains a challenge for vision-language models (VLMs) like CLIP, which struggle to understand complex and fine-grained relationships between images and text. Current fine-tuning methods aimed at improving compositionality often reduce performance in multi-modal tasks. This trade-off is mainly due to global hard negative loss applied to single vector representations, which fails to capture subtle differences between similar texts.
To overcome this limitation, we introduce $\texttt{FSC-CLIP}$, a new fine-tuning method for CLIP designed to enhance compositional reasoning without sacrificing multi-modal task performance. By incorporating local hard negative loss and selective calibrated regularization, our approach provides fine-grained supervision while preserving the integrity of multi-modal representations.
Our method is designed to fine-tune CLIP using hard negative captions, incorporating Local Hard Negative (LHN) Loss and Selective Calibrated Regularization (SCR) to improve compositional understanding while preserving multi-modal performance.
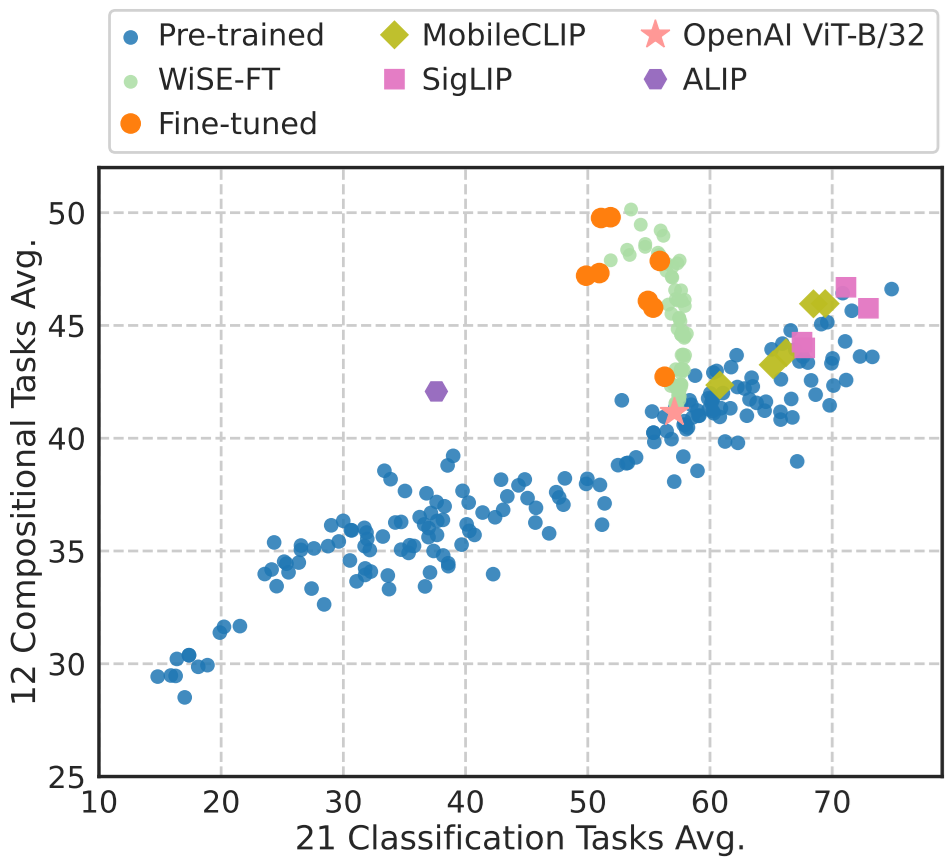
Also, please check out our $\texttt{vl-compo}$ package, which enabled the comprehensive evaluation across diverse tasks in our work. It supports evaluations for a wide range of compositional and multi-modal task benchmarks, integrating various pre-trained and fine-tuned VLMs, and is continuously evolving.
If you find our work useful for your research, please cite with the following bibtex:
@article{oh2024preserving,
title={Preserving Multi-Modal Capabilities of Pre-trained VLMs for Improving Vision-Linguistic Compositionality},
author={Oh, Youngtaek and Cho, Jae Won and Kim, Dong-Jin and Kweon, In So and Kim, Junmo},
journal={arXiv preprint arXiv:2410.05210},
year={2024},
}
@article{oh2024exploring,
title={Exploring the Spectrum of Visio-Linguistic Compositionality and Recognition},
author={Oh, Youngtaek and Ahn, Pyunghwan and Kim, Jinhyung and Song, Gwangmo and Lee, Soonyoung and Kweon, In So and Kim, Junmo},
journal={arXiv preprint arXiv:2406.09388},
year={2024},
}