Introduction
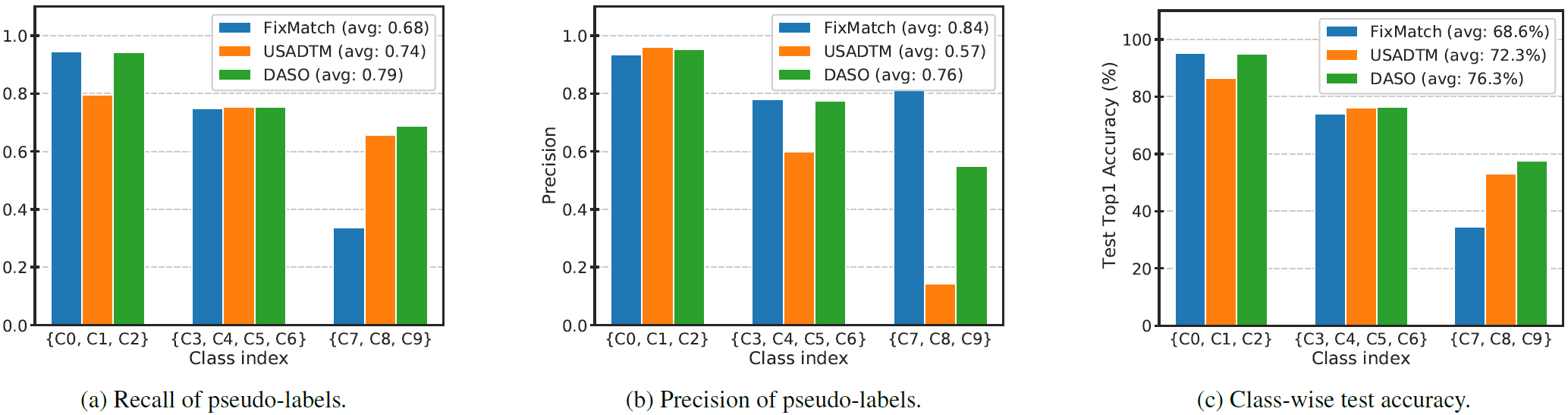
Many real-world datasets exhibit long-tailed distributions. With such class imbalanced data, semi-supervised learning (SSL) methods produce biased pseudo-labels, which can further bias the model during training. The bias of pseudo-labels also depends on class distribution mismatch between labeled and unlabeled data, in addition to the class-imbalance.
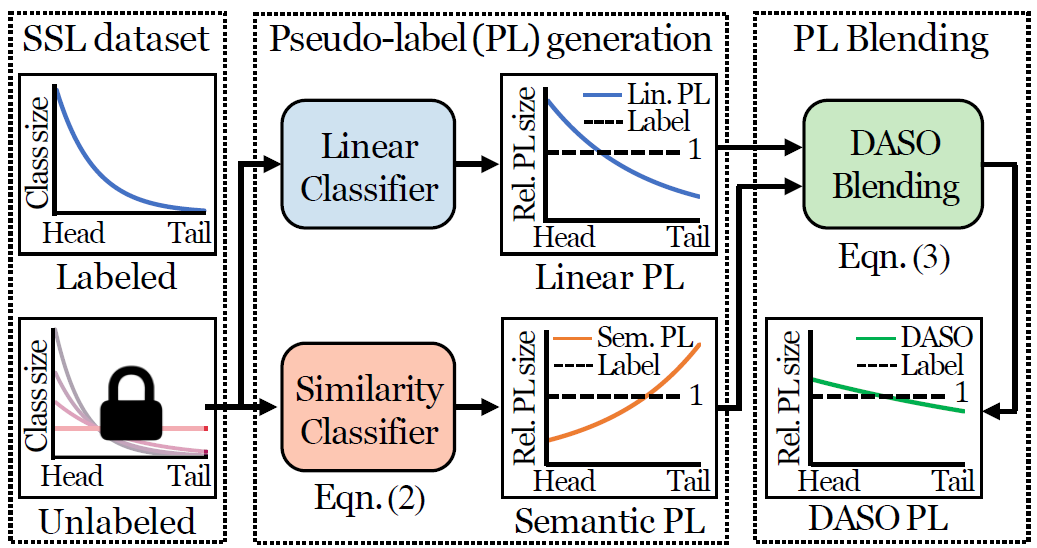
DASO reduces overall bias in pseudo-labels caused by imbalanced data, by blending two complementary pseudo-labels from different classifiers. We conceptually illustrate the bias as relative pseudo-label size, meaning that pseudo-label size is normalized by the actual label size.
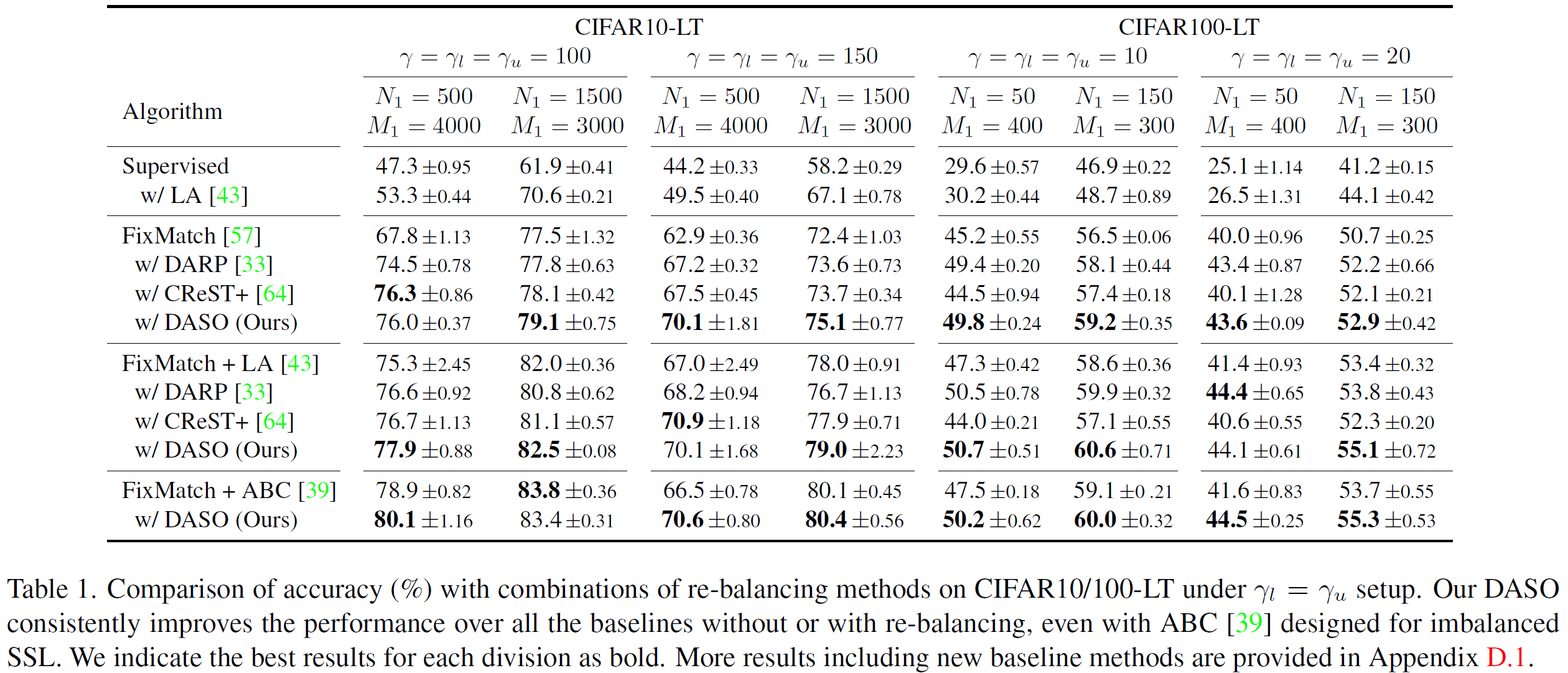
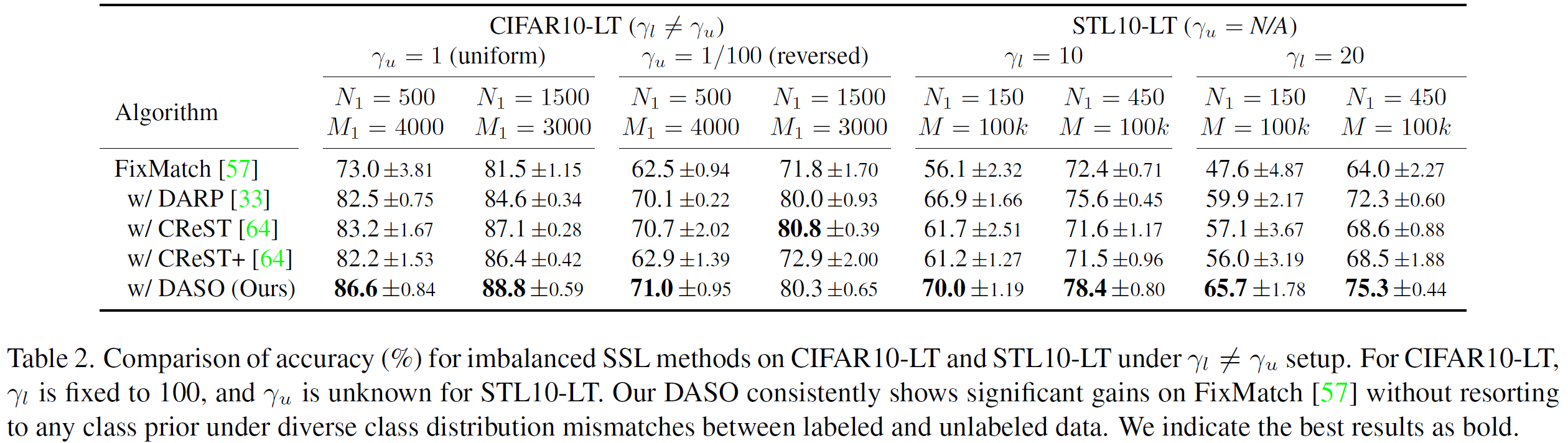
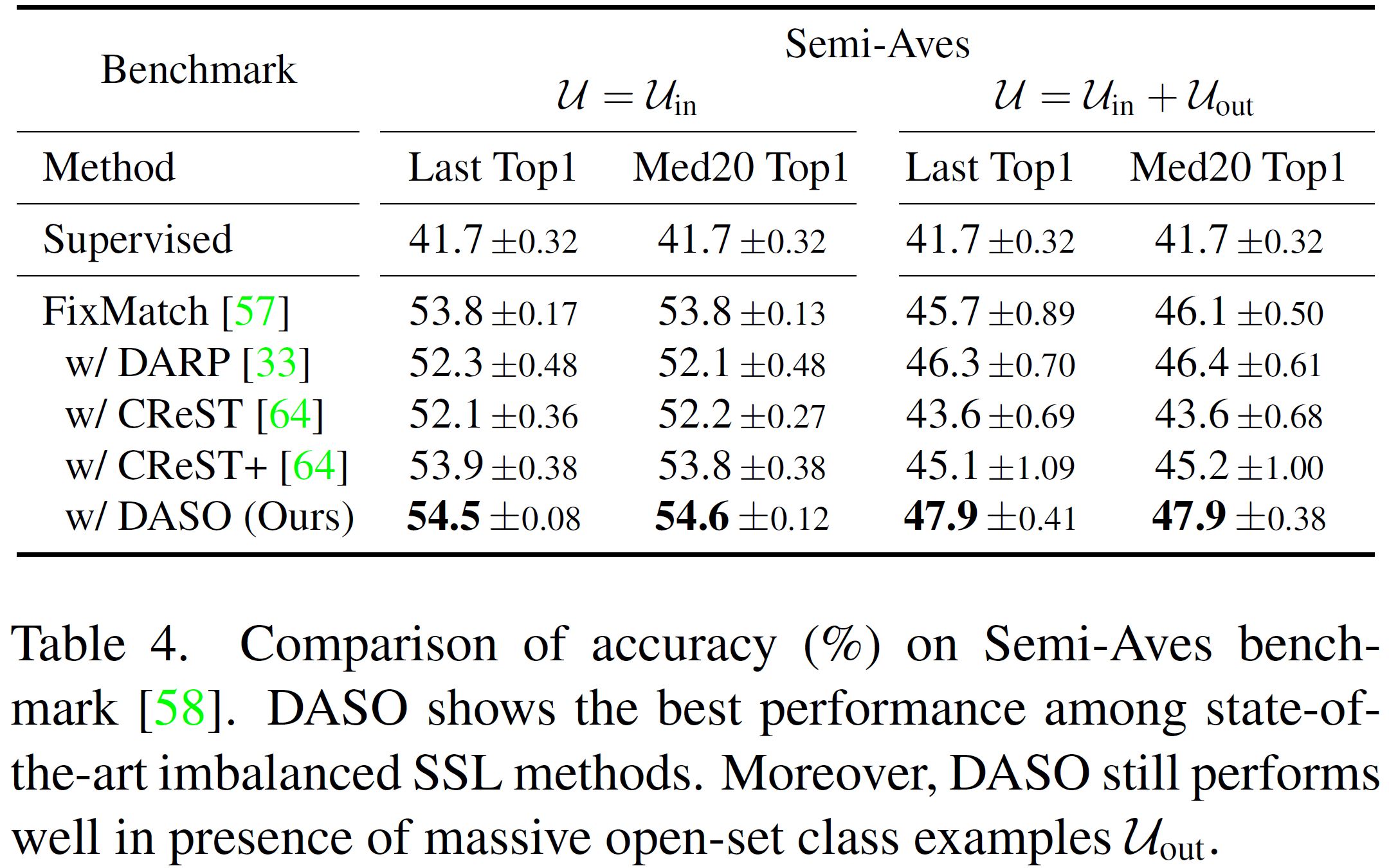
We present a new imbalanced SSL method for debiasing pseudo-labels under class-imbalanced data, while discarding the common assumption that class distributions of labeled data and unlabeled data are identical.